
I previously wrote a post about the real-time data processing architecture we have adopted at Gamesight. This post covers an open source tool that we created to reprocess data within our ELT pipeline - creatively named s3-sns-lambda-replay.
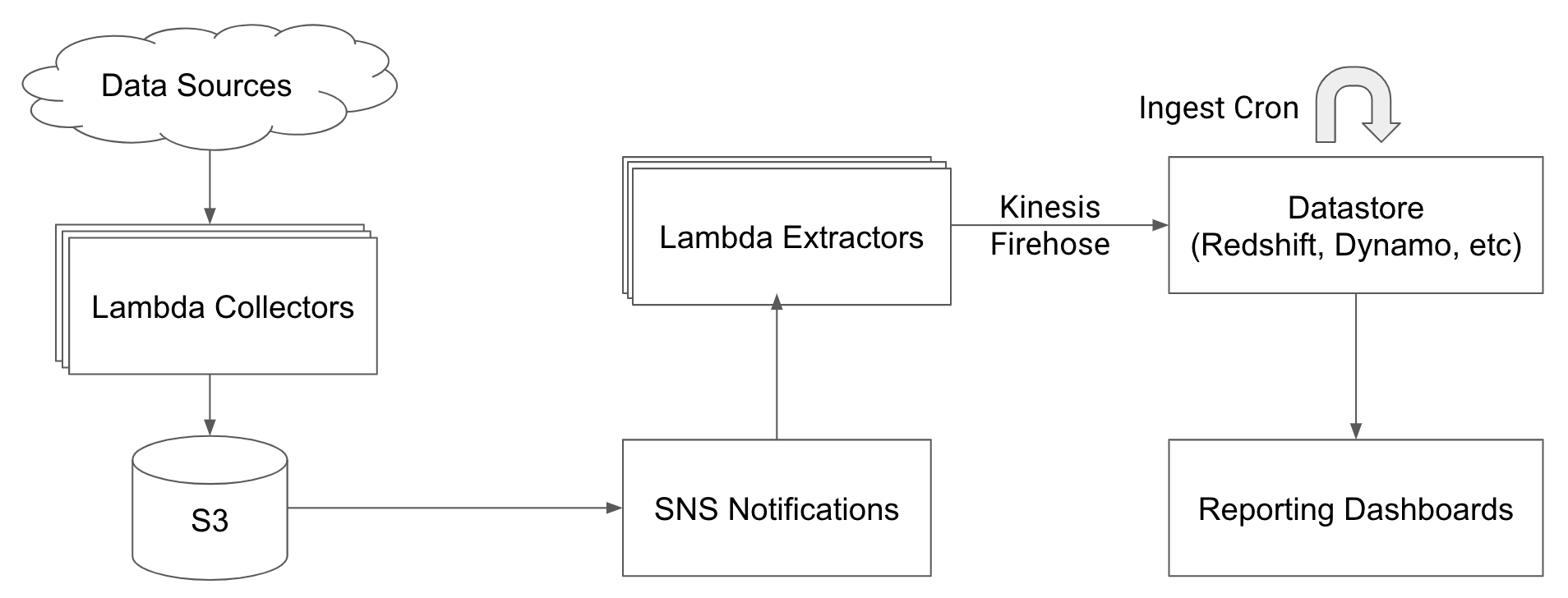
As a recap, to power our ELT pipeline we are relying on S3 Event Notifications to SNS. We then have data extraction Lambda functions which listen for new events through SNS and write rows into Redshift via Kinesis Firehose.
Jump To:
The problem
One weakness with our pipeline is that when we add new extractors for existing data we need to reprocess historical data from S3. Additionally, if an extract function fails irrecoverably - either from a bad deployment or a data model changes - we need a way to replay the records.
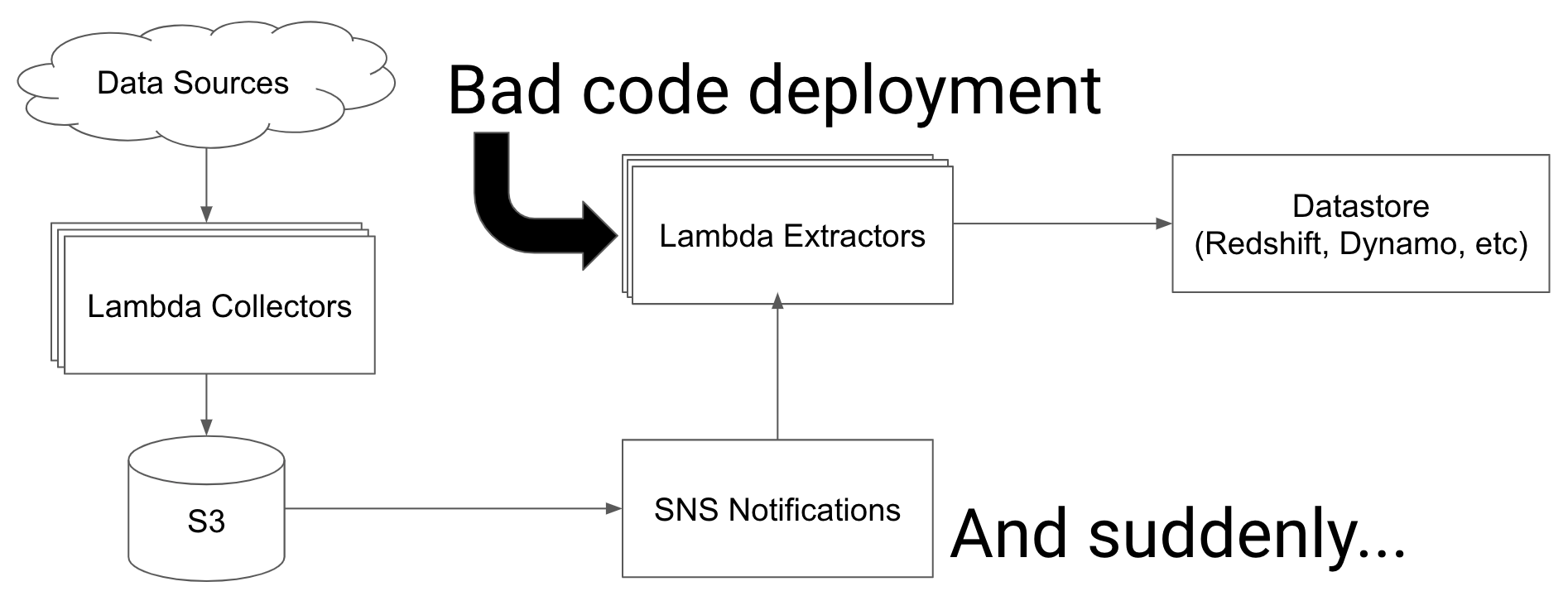
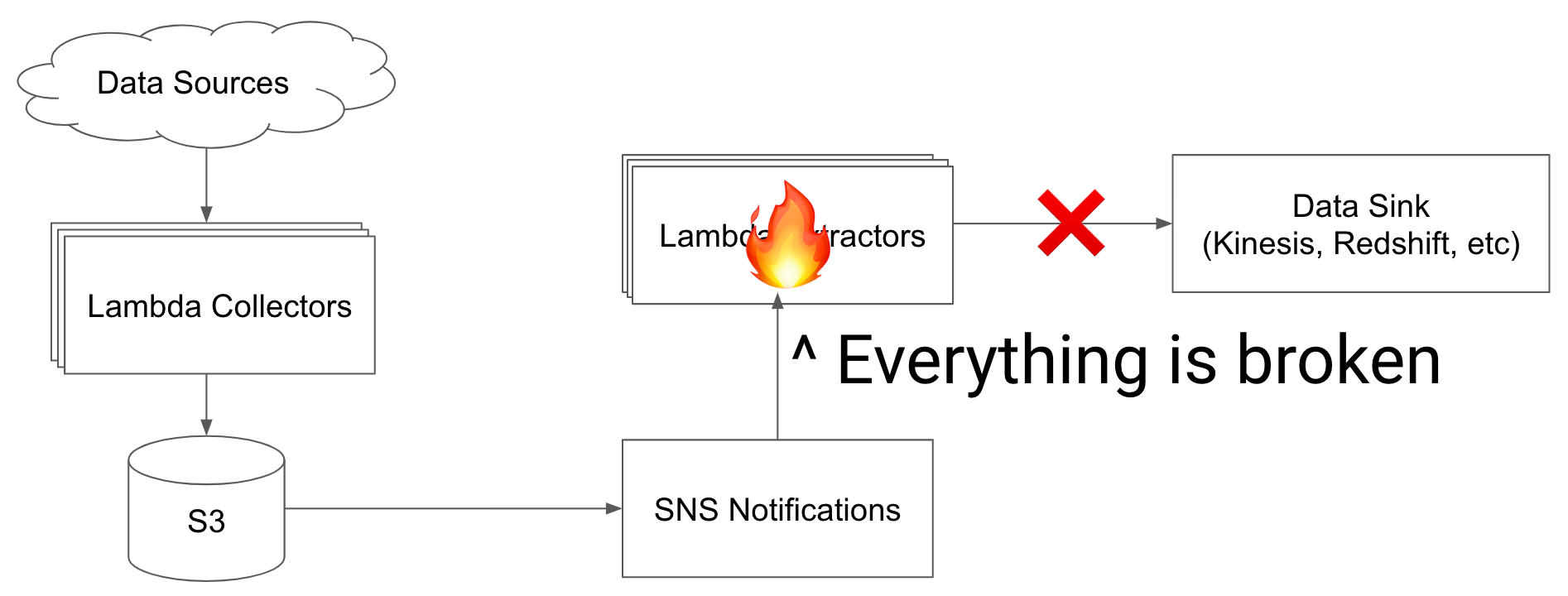
We need to be sure that everyone on the team was confident that they can spin up a new processing pipeline or fix a broken one without it becoming a huge operational burden.
How to use s3-sns-lambda-replay
To resolve these issues we built s3-sns-lambda-replay. S3-sns-lambda-replay aims to be a developer-friendly tool to make the process of replaying S3 file creation Lambda invocations stress-free and repeatable.
The tool is straightforward to use:
Use the interactive CLI to select the directories to replay data from
> python s3-lambda-replay.py ? Select the bucket which contains the files to be replayed: [my-data-lake] ? Browse to the path containing the files to be replayed. When at the proper path select the first and last item to be replayed: [clicks/] ? Browse to the path containing the files to be replayed. When at the proper path select the first and last item to be replayed: (Use arrow keys to move, <space> to select, <a> to toggle, <i> to invert) » ○ clicks/d=2021-01-03/ ○ clicks/d=2021-01-02/ ○ clicks/d=2021-01-01/Next you select which lambdas to send replay data to
? Select the bucket which contains the files to be replayed: (Use arrow keys to move, <space> to select, <a> to toggle, <i> to invert) » ○ arn:aws:lambda:us-west-2:123456789012:function:my-click-transformConfirm the configuration
################# # Replay Config # ################# S3 Bucket: my-data-lake S3 Paths : - clicks/dt=2021-01-03/ - (2 total) - clicks/dt=2021-01-02/ ################# Lambda Function(s): - arn:aws:lambda:us-west-2:123456789012:function:my-click-transform Batch Size Files : 25 Batch Size MB : 10.0 MB Concurrency : 10 ? Is this configuration correct? (y/N)- From here s3-sns-lambda-replay scans S3 for the files to replay, batch those files into mock SNS payloads, and begins triggering your Lambdas in parallel.
That's it, hope you find this tool to be useful! You can check it out on Github.